Sips and Stats: Seattle’s Best Coffee Spots Revealed
5 min read • June 18, 2025
Seattle’s coffee scene is iconic. But how does one cut through the hype to find the actual best spots? Atleast that is the problem I had in my initial days in the city and hence came the idea to explore the data for analysis.
YELP to the rescue! ;)
I used the Yelp API, unsupervised learning, geospatial clustering, and scaled review scores with some caffeine magic.
Data Collection
I pulled real-time data from Yelp’s Fusion API across Seattle, Bellevue, Kirkland, and Redmond. For each coffee shop, we extracted:
ratingreview_countprice_level(converted from $ to numeric)distancefrom city center- Geocoordinates (
latitude,longitude) - Business metadata like categories and open/closed status
Choosing the Right Number of Clusters
Used the Elbow Method to find the optimal number of clusters (k) based on rating, reviews, price, and distance.
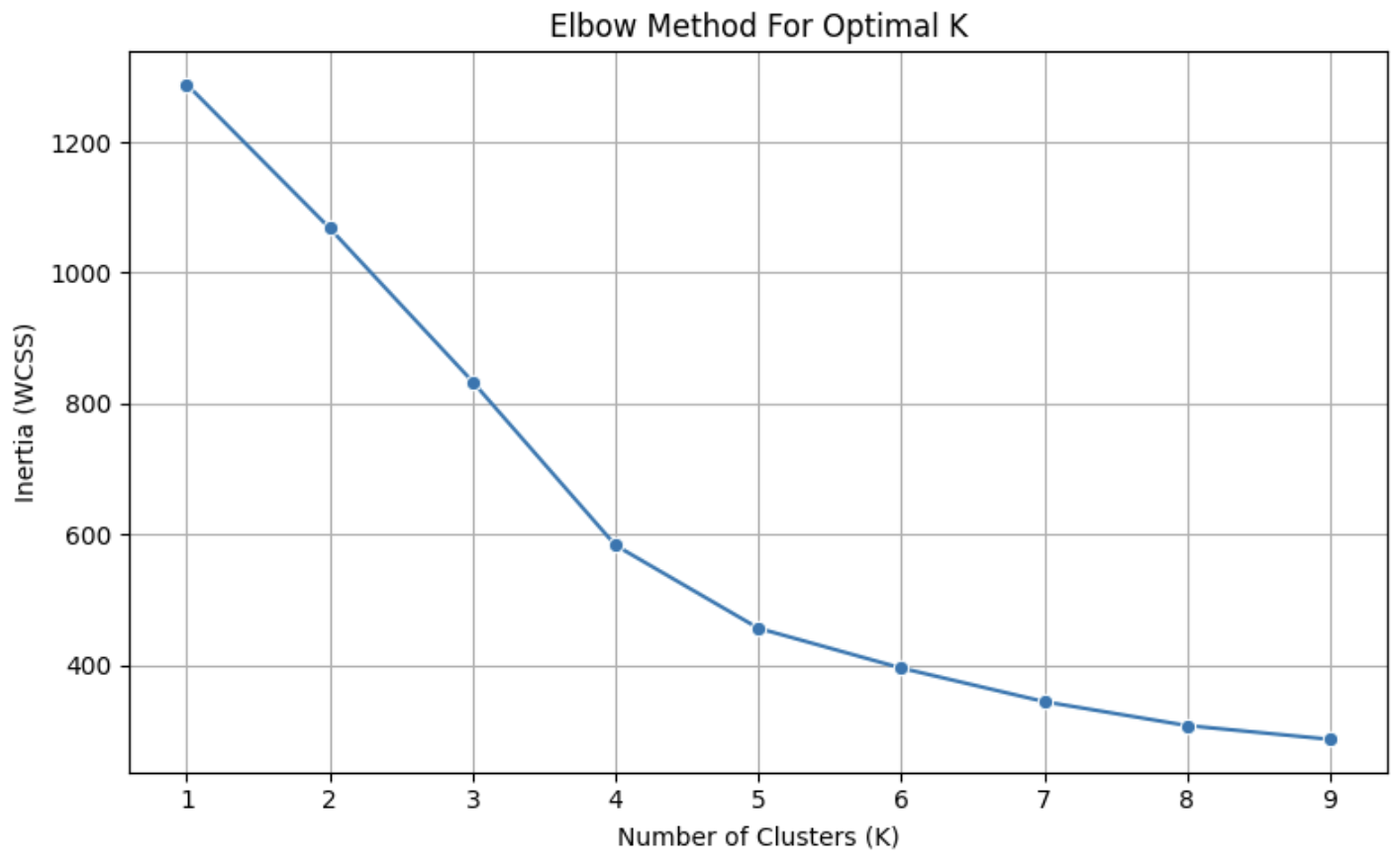
The elbow point clearly showed k = 4, which we used to form clusters with KMeans.
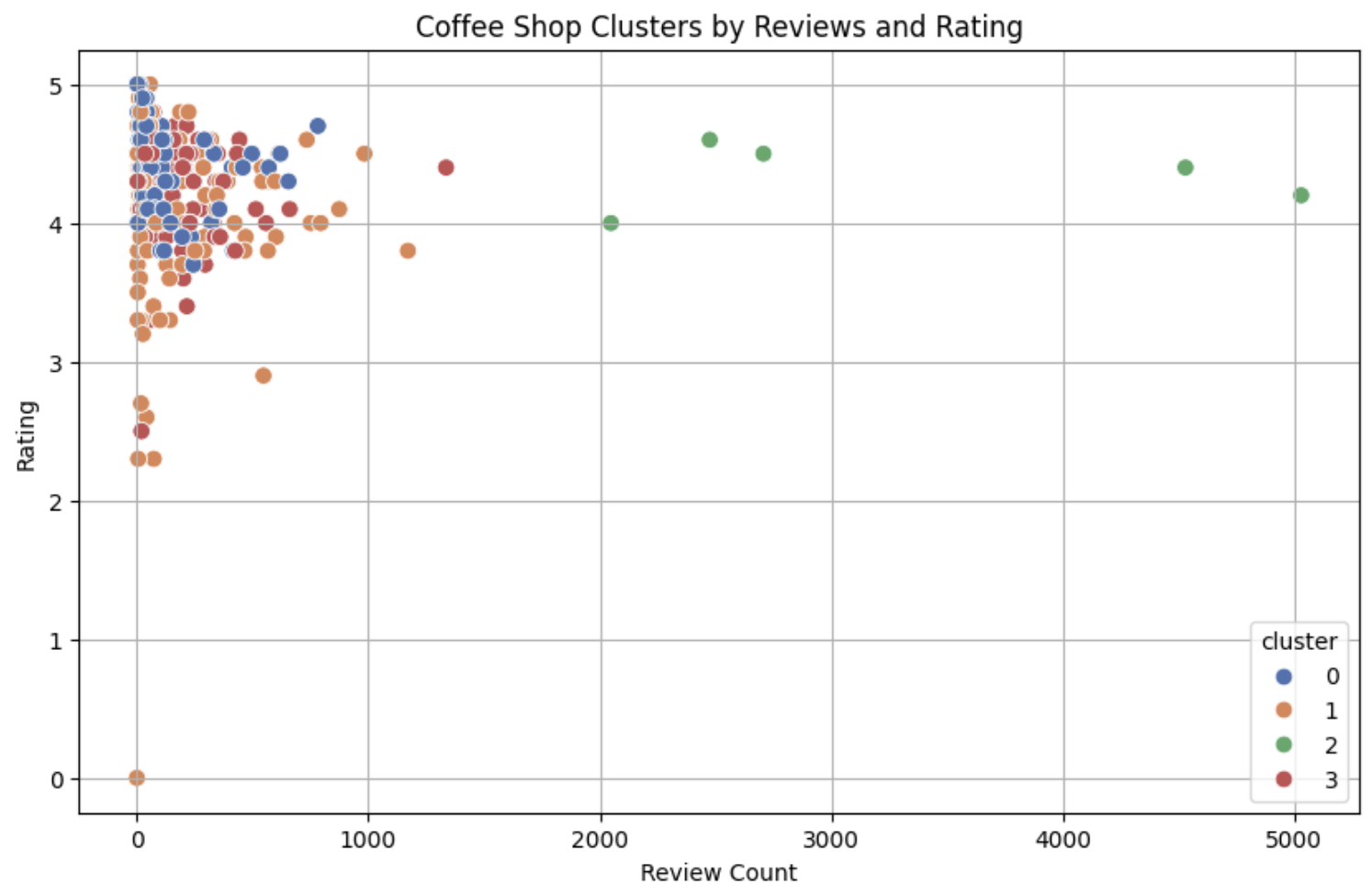
Clustering Seattle Coffee Shops
Each coffee shop was grouped into one of four clusters using:
ratingreview_countprice_leveldistance_km
These features were scaled using StandardScaler before clustering.
All clusters showed high average ratings (~4.0–4.7), but differed in price, location, and popularity. Something that justifies that coffee in Seattle has it’s own high benchmark standards :)
Map Visualization
We visualized the clusters on a folium map:
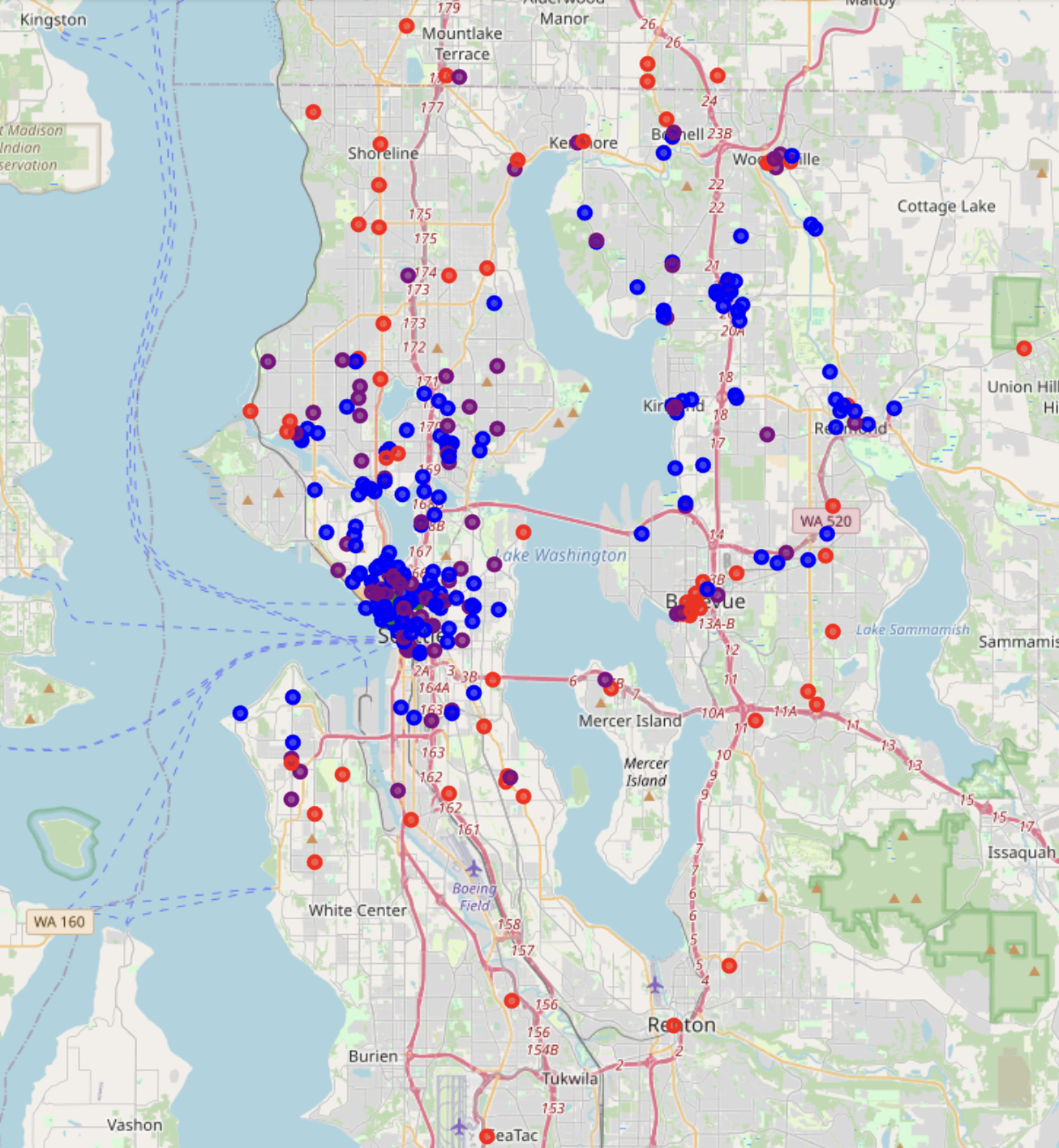
Each colored circle shows a coffee shop, color-coded by its assigned cluster.
Scaled Composite Score: Quality × Popularity
We created a scaled score to rank coffee shops by a balanced combination of quality and popularity.
from sklearn.preprocessing import MinMaxScaler
scaled = MinMaxScaler().fit_transform(df[['rating', 'review_count']])
df['scaled_rating'] = scaled[:, 0]
df['scaled_reviews'] = scaled[:, 1]
df['scaled_score'] = df['scaled_rating'] * df['scaled_reviews']This avoids raw dominance of review counts and highlights well-loved shops across the board.
Top 10 Coffee Shops by Scaled Composite Score
| Name | Location | Rating | Review Count | Scaled Score |
|---|---|---|---|---|
| Biscuit Bitch | 1909 1st Ave | 4.2 | 5030 | 0.840000 |
| Starbucks Reserve Roastery Seattle | 1124 Pike St | 4.4 | 4530 | 0.792525 |
| The Crumpet Shop | 1503 1st Ave | 4.5 | 2707 | 0.484354 |
| Storyville Coffee Company | 94 Pike St | 4.6 | 2474 | 0.452501 |
| Top Pot Doughnuts | 2124 5th Ave | 4.0 | 2048 | 0.325726 |
| Biscuit Bitch | 2303 3rd Ave | 4.3 | 1829 | 0.312712 |
| Moore Coffee Shop | 1930 2nd Ave | 4.4 | 1335 | 0.233559 |
| Anchorhead Coffee - CenturyLink Plaza | 1600 7th Ave | 4.5 | 983 | 0.175885 |
| Coffeeholic House | 3700 S Hudson St | 4.7 | 782 | 0.146139 |
| Espresso Vivace Roasteria | 532 Broadway Ave E | 4.1 | 874 | 0.142481 |
💸 Best Value-for-Money Coffee Spots
To surface affordable gems, we also calculated:
value_score = rating / price_levelThis helps highlight high-rated spots with lower price points.
🔟 Top 10 Value-for-Money Coffee Shops
| Name | Rating | Price | Price Level | Value Score |
|---|---|---|---|---|
| Overcast Coffee Company | 4.8 | $ | 1.0 | 4.8 |
| URL Coffee | 4.7 | $ | 1.0 | 4.7 |
| The Bridge Coffee House | 4.7 | $ | 1.0 | 4.7 |
| Sound & Fog | 4.7 | $ | 1.0 | 4.7 |
| Experience Tea | 4.7 | $ | 1.0 | 4.7 |
| C.C Espresso and Ice Creamery | 4.7 | $ | 1.0 | 4.7 |
| Cafe Argento | 4.6 | $ | 1.0 | 4.6 |
| Squirrel Chops | 4.6 | $ | 1.0 | 4.6 |
| Phin | 4.6 | $ | 1.0 | 4.6 |
| The Station | 4.6 | $ | 1.0 | 4.6 |
🧠 What We Learned
- Seattle’s coffee scene is remarkably high-rated across the board
- Review count isn’t always correlated with value
- Clustering helps organize the scene; scoring helps spotlight the stars
🚀 Next Steps
- Use time-decay scoring for recent reviews
- Sentiment analysis from textual reviews
- Cluster-specific rankings (e.g., best hidden gem)
Explore the code and try your own ranking here:
🔗 Open the Colab Notebook
If you enjoyed this, follow Vishnu on LinkedIn or check out more blogs at mlgyaan.com for practical machine learning, data science, and storytelling with code.